
.jpg)

雷锋网 AI 科技评论按:在之前的文章 Uber论文5连发宣告神经演化新时代中,我们介绍了 Uber AI Lab 在深度进化算法方面的研究成果,从多个角度展现了进化算法解决强化学习问题的能力,也展现了进化策略 ES(evolution strategies)与梯度下降之间的联系。这些研究成果非常精彩、给人启迪。不过当时我们没有提到的是,这些成果消耗了相当多的计算资源:实际上论文中的实验是在 720 到 3000 个 CPU 组成的大规模高性能计算集群上运行的,这样的集群固然有充沛的计算能力运行进化算法,但在 Uber AI Lab 的研究人员们看来,这种级别的计算能力要求也就把领域内多数的研究人员、学生、企业以及爱好者拦在了门外。
近日 Uber AI Lab 开源了一组进化算法代码,它的特点是可以高速(同时也更廉价地)进行进化策略研究。根据介绍,训练神经网络玩 Atari 游戏的时间可以从原来在 720 个 CPU 组成的集群上花费 1 个小时,到现在在一台桌面级电脑上只需要 4 个小时。这一点很重要,因为它极大地刷新了我们对进行这类研究所需的资源多少的认识,从而使更多的研究人员能够着手研究。雷锋网 AI 科技评论下面对其中的改进做个详细的介绍。


神经进化技术是解决具有挑战性的深层强化学习问题的一种有竞争力的替代方案,如玩 Atari 游戏以及模仿人类运动。图示出了用简单遗传算法训练的深度神经网络的行为。
是哪些修改使它更快,且可在单台计算机上运行?
实际上,拥有多个虚拟内核的现代高端桌面 PC 本身就像一个中型计算集群。如果能正确地并行执行训练过程,在 720 个核心上如果需要运行 1 个小时的训练过程,在带有 48 核 CPU 的个人计算机上运行就需要 16 个小时。这虽然也是较慢的,但不会令人望而却步。不过,现代台式机还有 GPU,它们运行深度神经网络(DNN)的速度很快。Uber AI Lab 的代码能够最大化并行使用 CPU 和 GPU。它在 GPU 上运行深度神经网络,CPU 上运行要训练的这个任务(例如电子游戏或物理仿真器),并可以在每个批当中并行运行多个训练过程,从而可有效地利用所有可用的硬件。如下所述,它还包含自定义的 TensorFlow 操作,这显著提高了训练速度。
允许在 GPU 上进行训练需要对神经网络的计算过程进行一些修改。在 Uber AI Lab 的研究人员的设置中,单个神经网络在单个 CPU 上的速度比在 GPU 上更快,但是 GPU 在大批量类似的并行计算(例如,神经网络的前馈传播)时有很大好处。为了尽量榨干 GPU 的计算能力,他们将多个神经网络的前馈传播聚合成批次。这样做在神经网络研究中是常见的,但通常是同一个网络处理不同的输入。然而,进化算法中上有一批参数不同的神经网络,但是即使网络不同,也可以用同样的做法进行加速(虽然内存的需求会相应增加)。他们用基本的 TensorFlow 运算实现了神经网络群的批量操作,并且它产生了大约 2 倍的加速,把训练时间减少到了大约 8 小时。
不仅如此,研究人员们还觉得他们可以做得更好。虽然 TensorFlow 提供了所有需要的运算指令,但这些运算并不那么适合于这种类型的计算。因此,他们添加了两种自定义的 TensorFlow 运算,加起来可以再把速度提升两倍,相比在之前一台机器上最初提到的 16 小时,将训练减少到大约 4 小时。
第一种定制的 TensorFlow 运算显著加快了 GPU 上的运算速度。它是专为异构神经网络计算定制的,在 RL 领域,每步运算操作所需时间具有不同的长度,这在 Atari 游戏和许多模拟机器人学习任务中是确实存在的。它允许 GPU 只运行需要运行的那几个网络,而不需要在每次迭代中都运行整批固定的网络集。
到目前为止所描述的改进使得 GPU 比 CPU 更具成本效益。事实上,GPU 是如此之快,以至于运行在 CPU 上的 Atari 模拟器无法跟上,即使已经使用了多处理库做并行化加速计算。为了提高仿真性能,研究人员们添加了第二组定制的 TensorFlow 运算。这些将 Atari 模拟器的接口从 Python 改为定制的 TensorFlow 命令(reset,step,observation),利用了 TensorFlow 提供的多线程快速处理能力,因而没有 Python 与 TensorFlow 交互时的典型速度下降问题。
总的来说,所有这些变化使得雅达利模拟器获得了大约 3 倍加速。这些创新应该可以加快任何有多个并行任务实例的强化学习研究(例如 Atari 游戏或 MujoCo 物理模拟器),这种多实例的做法在强化学习中也是越来越常见,例如分布式深度 Q 学习(DQN)和分布式策略梯度(例如A3C)。
只要有能力在 GPU 上运行多个网络和及在 CPU 上运行更快的任务模拟器,挑战就只剩下了如何让计算机上的所有资源尽可能地运行。如果我们对每一个神经网络做了一个前馈传播,询问它在当前状态下应该采取什么行动,那么当每个神经网络都在计算答案时,运行游戏模拟器的 CPU 就空闲下来了。同样,如果我们采取了行动,并问任务模拟器「什么状态会从这些行为中产生?」在模拟步骤中,运行神经网络的 GPU 将空闲(注:下图的左 1)。如果改为了(下图的第 2 个)多线程 CPU + GPU 选项,从图中可以看到虽然改进了单线程计算,但仍然是低效的。
一个更好的解决方案是将两个或多个神经网络子集与模拟器配对,并且始终保持 GPU 和 CPU 同时运行,这取决于准备采取哪一个步骤(神经网络或模拟器)来更新来自不同集合的网络或模拟器。这种方法是最右边的「流水线 CPU + GPU」选项,如下图右 1 所示。通过它以及上文提到的其他改进,使得我们训练 4 百万参数的神经网络所需时间降到在一台计算机上只需 4 小时。
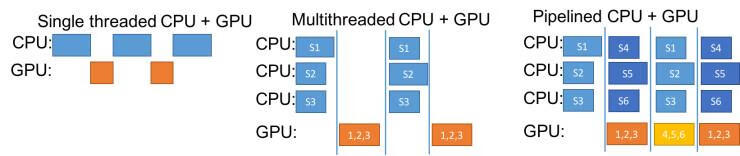
在 RL 中优化异构网络的种群调度。蓝色框是任务模拟器,比如 Atari 模拟器或像 MujoCo 这样的物理引擎,它可以有不同长度的运行时间片。直白的运行方式虽然使用了 GPU(左)但性能低,原因有两个:1)GPU 的批大小为 1,没有利用它的并行计算能力,2)存在 GPU 等待 CPU 的空闲时间,反之亦然。多线程方法(中间)允许通过多个 CPU 并行地运行模拟器,来减少 GPU 的等待时间,但是当 CPU 工作时,GPU 空闲,反之亦然。Uber AI Lab 设计的流水线实现(右)允许 GPU 和 CPU 有效地运行。这种方法也适用于同时运行的多个 GPU 和 CPU,实际上他们也就是这样做的。
实验更快、更便宜后的意义
Uber AI Lab 的代码使研究社区的每一个人,包括学生和自学成才的学生,能够快速实验性地反复训练诸如玩 Atari 游戏的挑战性深度神经网络,而后者是迄今为止仅限于资金充足的工业和学术实验室的奢侈品。
更快的代码会带来研究进展。例如,新代码使 Uber AI Lab 能够只花很少的成本就可以为遗传算法展开一个广泛的超参数搜索,与他们最初报告的性能相比,将改进大多数 Atari 游戏的性能。论文已经发表在 arXiv。同样地,更快的代码也催化了研究的进步,通过缩短迭代时间来改进深度神经进化,使他们能够尝试更多的任务中的每一个新的想法,并且更长时间地运行算法。
Uber AI Lab 的新软件库包括深度遗传算法的实现、来自 Salimas 等人的进化策略算法,以及(非常具有竞争力的!)随机搜索控制。他们由衷地希望其他人也使用他们的代码来加速自己的研究活动。他们也邀请整个研究社区参与构建我们的代码并改进它,例如,分布式 GPU 训练和添加为这种类型的计算定制的其他 TensorFlow 运算时,有可能获得进一步的运算提速。
深度神经进化领域的研究现在非常火热。除了 Uber AI Lab 自己的研究和 OpenAI 的研究,最近也有来自 DeepMind、谷歌大脑和Sentient的深度学习进展。Uber AI Lab 希望通过开源使他们的代码有助于这个领域的发展。
以及最根本地,Uber AI Lab 的目标是降低进行这项研究的成本,使所有背景的研究者能够尝试自己的想法来改进深层神经进化,并利用它来实现他们的目标。
即便文中提到的 48 核 CPU 「桌面 PC」引起了一些争议(7k 人民币的 AMD 锐龙 Threadripper 1950X16 核 32 线程,15k 人民币的 Intel i9 7980XE 18 核 36 线程),但也确实是十分有价值的研究成果。雷锋网
相关推荐
-
熊猫酒仙服务器部落(魔兽世界熊猫酒仙服务器)
只单英雄打电脑,可出兵,无2发3发英雄。声明:以炼金,地精修补匠(人族),兽王雷克萨,熊猫酒仙(兽族),娜迦女海巫,火焰巨魔(暗夜),黑暗游侠,深渊魔王(亡灵)。 v(人族):简单和中等难度电脑,步兵和猎头都行,中后期可加点其它兵种,萨满_巫医_飞龙_蝙蝠等。疯狂电脑,1-2本爆斧头兵快速怼死电脑
-
王者更新时间是多少(赛季皮肤会返场吗)

相信小伙伴们都知道,王者荣耀S18新赛季很快就要开始了,虽然官方一直没有官宣更新时间,但通过其他的渠道我们可以猜出新赛季更新时间,赶紧来看看吧!如果此次官方不鸽的话,那么按照关联应用的提示,以及游戏中推送蒙犽信息,种种现象都表明就应该是在9号迎来新版本强者之路的更新。按照惯例,每一次的大版本更新都会
-
熊猫功夫观后感(功夫熊猫 虎)




欧美经典动画娴熟的技术、精彩的内容、俏皮的对白,让我们如痴如醉。这些经典的动画片在给我们带来无数快乐欢笑的同时,也奉上了一句句至理名言,让我们在笑过之后有所思考。下面让我们重温一下这些经典动画中的经典对白。The Lion King《狮子王》I’m only brave when I have to
-
冒险岛双弩精灵技能效果(冒险岛双弩精灵技能装备)
冒险岛手游今天上线了一种新职业,那就是双弩精灵,不少玩家对双弩精灵不太了解,那么冒险岛手游双弩精灵职业怎么样?双弩精灵厉害吗?现在小编就为各位玩家带来了冒险岛手游双弩精灵职业解析,希望能在游戏里帮到各位玩家!冒险岛手游双弩精灵厉害吗?双弩精灵定位:远程输出型职业特点:远程、技能华丽,输出爆表具体实力
-
天梯积分怎么算(天梯分数怎么看)




诸君安好,雾夏菌报道。前几天几乎所有人的关注点都在新限定白胡子的身上,因此忽略了不少内容,而天梯的改版便是其中之一。作为一款养成游戏,天梯这方面原本是用来吸引玩家进行竞赛角逐的,但因为机制的原因,很长一段时间,让大部分玩家望而却步,根本不去参与其中。而天梯商店的积分兑换限制,也让不少玩家吐槽。积分商


版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请通知我们,一经查实,本站将立刻删除。