
.jpg)
作者:仵冀颖
编辑:Joni Zhong
本文将探讨人机交互中的注意力问题。
本文我们关注注意力(Attention)问题。在这里,我们谈到的注意力与大家非常熟悉的机器学习中的注意力模型(Attention Model,AM)不同,本文讨论的是人机交互中的注意力问题。
人机交互中的这种注意力也被称为是用户的关注焦点(User\'s focus Of Attention)。人机交互中的注意力是构造社交机器人(Social Robot)的重要问题,也在普适计算和智能空间等人机交互应用中起到非常重要的作用,因为在这些应用中,必须能够持续的监控用户的目标和意图。
通过引入并有效测量注意力,能够改进人机交互的方式、效率和效果。一般认为,主要通过眼睛注视(Eye gaze)和头部姿势动态(Head)等来确定注意力 [1]。针对这些测量指标,研究者需要结合机器视觉和其他传感技术,测量和计算交互中的注意力指标,并且利用这些指标对机器人的行为进行控制。另一方面,这些指标也可以作为衡量社交机器人或者机器人辅助治疗中的效果。
本文首先介绍了一种用于社交机器人的人机交互方法,该方法根据目标人当前的视觉注意力焦点来吸引和控制目标人的注意力,从而建立人和机器人之间的沟通渠道。这也是社交机器人中注意力的最直接的研究和应用。此外,本文还介绍了两个在人与机器交流场景中的注意力应用,一是将注意力应用于在线教育效果的评估,另一个是在机器人增强治疗中开发自闭症儿童的联合注意力(Joint Attention,JA)。
一、Supporting Human–Robot Interaction Based on the Level of Visual Focus of Attention

论文地址:https://ieeexplore.ieee.org/abstract/document/7151799
在社交机器人的构造过程中,为了使机器人能够在服务应用程序或协作工作场景中与人类进行有效的交互,应该将这些机器人视为社会参与者,并表现出社会智能和意识。本文提出了一种智能的社交机器人工作方法,能够根据目标人的视觉注意力水平(Level of visual focus of attention,LVFOA)吸引目标人的注意力,并建立与目标人的交流通道。
作者认为 VFOA 是机器人能够有效吸引注意力(用户关注点)和启动互动的一个重要线索,因为:1)它有助于理解人在做什么,2)它表明关注目标客体是谁(谁在看谁)。本文使用视觉线索,例如注视模式(Eye gaze),以及目标人的任务背景来识别 VFOA 及其水平。
1. VFOA 介绍
人们一般都会倾向于注视他 / 她感兴趣的目标物体 [2],为了描述参与人机交互任务的目标人的注意力情况,本文定义了视觉注意力(Visual Focus of Attention,VFOA)为三维表示的注视方向(gaze direction)。而具体任务 Ti 定义为:Ti(T={阅读、写作、浏览、观看绘画)},其中,i=1...4,Ti 是属于有限组可视目标 Li 的元素,而 Li 就是由不同任务的不同目标对象组成。例如,L1={book},L2={notebook},L3={display,keyboard,mouse} 和 L4={paintings},分别用于阅读、写作、浏览和查看绘画任务。作者定义了当目标人从指定的目标对象转移其 VFOA 时如何度量其注意力的丧失,还定义了如何测量目标对象参与任务时 VFOA 的持续时间。
本文对 18 名参与者(14 名男性,平均年龄 28 岁,标准差 4.9)完成四项任务的过程进行了录制:阅读(4 名参与者)、写作(4 名)、浏览(6 名)和观看绘画(将注意力集中在室内的一幅画上,4 名)。给参与者发出的指令是要求他们集中精力完成任务。每个人阅读、写作、浏览和观看绘画的平均任务完成时间分别为 9 分钟、9 分钟、8 分钟和 8 分钟。
为了测量 VFOA 的持续时间,作者观看录制的视频数据,并手动标注(使用暂停和重新开始)参与者在没有失去注意力的情况下对任务产生一致结果的时间段。当受试者将当前的 VFOA 转向另一个方向时,就会出现注意力丧失的情况。对于阅读和写作,参与者分别在「翻页」和「停止写作」时失去注意力。对于阅读、写作、浏览和观看绘画的任务,分别检测到 14 次、10 次、9 次和 12 次注意力的丧失情况。根据这些情况的持续时间,估计得到了每个任务的 VFOA 时间跨度(见表 1)。
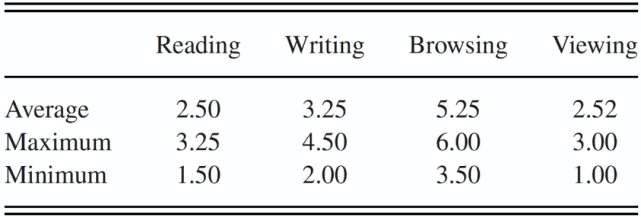
表 1. VFOA 持续时间(分钟)
2. 本文方法介绍
本文所提出的方法如图 1 所示。在启动交互模块(见图 1(a)的左侧部分),机器人识别并跟踪目标人的 VFOA。如果它们最初是面对面的,机器人会产生一个感知信号,并与目标人进行眼神接触。否则,机器人会试图通过识别目标人当前的任务来吸引目标人的注意力。机器人检测当前 VFOA 的水平,直到时长达到 T_s(T_s 为预先设置的用于表示 VFOA 持续的最大时间跨度的参数)。图 1(b)给出了这一方法的具体执行步骤。机器人在时间 t 使用低级或高级的 VFOA(取决于目标人的当前任务),根据目标人的移位 VFOA 的观察情况来生成吸引注意力(Attention attraction,AA)信号(弱或强)。
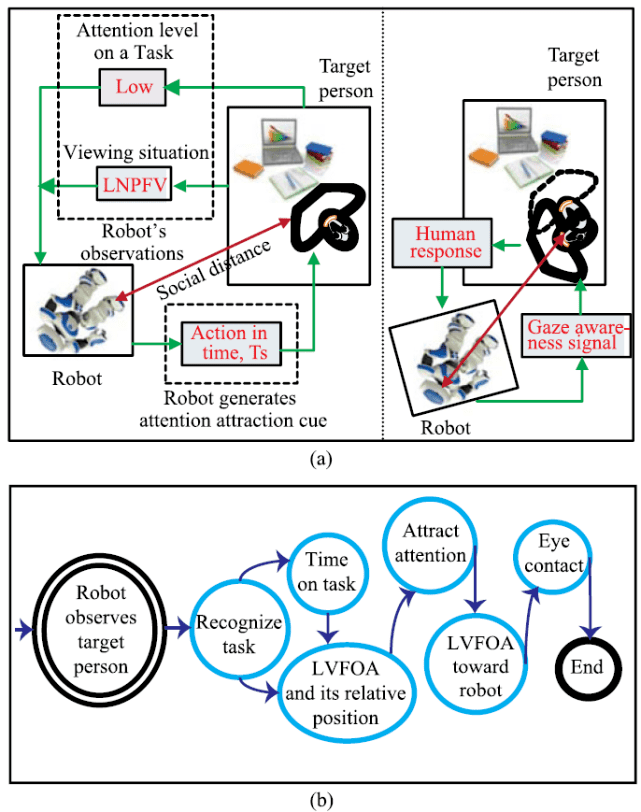
图 1.(a) 本文提出的方法的抽象视图;(b) 本文方法的基本步骤。
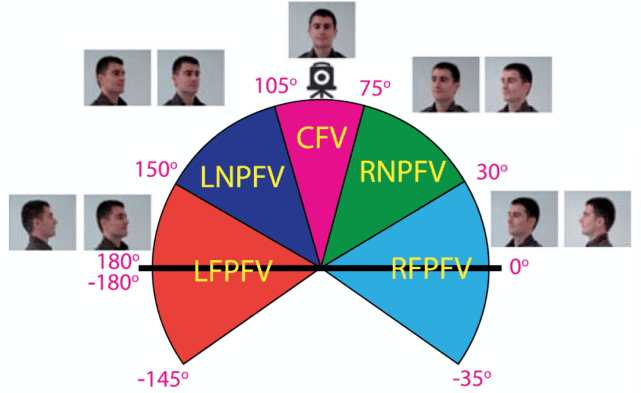
图 2. 头部方位分为五个角区域,其中使用的人脸图像来自远 GTAV 人脸数据库 [3]。
由图 2,本文作者将一个人的视野(Field of View,FOV)分为中心视野和周边视野,具体包括下面三个分区:
中心视野(Central Field of View,CFV):这个视野位于人类视野的中心。该区域设置为 30° 的锥形区域(图 2 中为 75° 至 105°);
近周边视野(Near Peripheral Field of View,NPFV):定义为 CFV 区两侧 45° 扇形区域。在 CFV 的右侧(图 2 中为 30° 到 75° 之间),该区域被定义为右侧近周边视野(RNPFV),而在左侧(图 2 中为 105° 到 150° 之间),该区域被称为左侧近周边视野(LNPFV);
远周边视野(Far Peripheral Field of View,FPFV):这个视野存在于人视野边缘的两侧,具体包括右侧远周边视野(RFPFV)和左侧远周边视野(LFPFV)。
如果在 CFV/LNPFV/RNPFV 中检测到 VFOA,则机器人会产生头部转动动作(微弱信号)。如果检测到的 VFOA 在 LFPFV 或 RFPFV 中,则机器人产生摇头动作(强信号)。当机器人成功吸引目标人的注意时,通信信道建立模块(图 1(a)的右侧部分)尝试与目标人建立通信信道。机器人决定了注意力转移的程度,并向目标人发出一个感知信号,表明它想和她 / 他交流。机器人通过眨眼完成眼神交流。
2.1 视觉注意焦点的识别及其水平
本文重点关注的是:持续的注意力(Sustained Attention)和集中或转移的注意力(Focused or Shifted Attention)。集中注意力或转移注意力是由刺激或意外事件所导致的瞬时反应,而持续的注意力则是由任务决定的。本文根据视觉信号(Visual Cues)和注视模式来衡量 VFOA 及其水平。
1)获取视觉信号。一是,使用视觉机器的 faceAPI 来检测和跟踪目标人的头部姿势 h_p。二是,使用光流特征检测头部运动 h_m [4]。三是,重叠面窗口:如果检测到一个面部并且与最近的头部运动窗口重叠,h_m 大于 50%,则认为检测到重叠的面部窗口 o_f(o_f=1)。检测到重叠面窗口就意味着目标人把脸转向了机器人。本文使用 Viola-Jones AdaBoost-Haar-like 人脸检测器检测人脸 [5]。
2)注视模式分类。一个人的注视模式表明了他 / 她感兴趣的对象。一般来说,人类的注视模式分为三种。当一个人在没有任何特定任务的情况下观看场景时,也就是说,当她 / 他「只是看到」场景时,就发生了自发的观看(Spontaneous Viewing)。当一个人带着特定的问题或任务(例如,她 / 他可能对博物馆中的某一幅画感兴趣)观看场景时,会出现任务或场景相关的观看(Task or Scene-Relevant Viewing)。当受试者不太注意自己在看什么,而是在关注一些「内心的想法」时,就会出现思维观察的取向(Orientation of Thought Viewing)。本文讨论的是前两种注视模式,使用 SVM 进行两类注视模式的分类处理。

图 3. (a) 检测到的头部及其在图像中的位置。(b) 提取人脸特征点。(c) 基于人脸特征点的眼睛区域估计。(d) 检测到眼睛区域内的虹膜中心。
为了得到注视模式 Gp,本文考虑了头部在图像中的平移运动和虹膜在眼睛中的位置变化。图 3 给出了本文实验定位人头部的过程。首先定位到头部区域,之后利用 ASM 找到面部特征点,最后定位到虹膜中心。令 H_0 表示初始头部位置,E_t 为第 t 帧的眼睛注视位置(眼睛中相对虹膜位置)。T_Ht 表示来自 H_0 的头部运动的平移矢量,则第 t 帧的注视点 Q_t 确定如下:
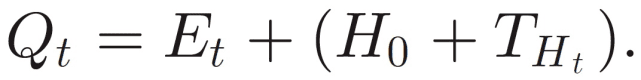
Gp={Q_0,Q_1, ...,Q_L−1} 表示 L 帧的注视模式。图 4(a)示出了观看场景中的特定点(任务或与场景相关的观看)的人的注视模式,并且在图 4(b)中示出如何观看三个不同点(自发观看)。

图 4. 注视模式:(a)与任务或场景相关的观察;(b) 自发观看。
通过对注视模式的重心进行归一化处理,从注视模式数据中提取特征向量。假设 C_m 是重心,r_t 是从 C_m 到注视点 Q_t 的欧氏距离:
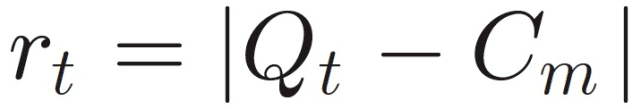
其中,t=0,1, ...,L−1。接下来,将距离值 r_t 按降序排序,并构造分类器的特征向量。使用 SVM 进行分类。
为了进行训练,作者收集了注视数据,并构建与场景相关的、自发观看的注视模式的训练数据。SVM 模型能够将注视模式分类为自发观看(spontaneous viewing)S_l 和任务或场景相关观看(task or scene-relevant viewing)T_l。
最后,通过识别目标人物所参与的任务来确定任务上下文(Task Context)。给定一个视频序列,提取每帧的方向梯度(HOG)特征直方图 [6]。将 HOG 特征组合为 10 个连续的帧来构建 HOG 特征模式 HOG_P:
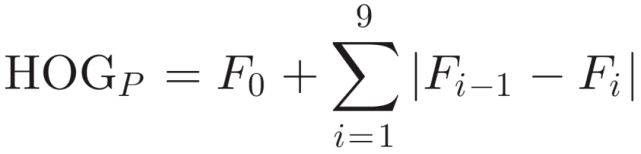
其中 F_0 和 F_i 分别是第一帧和第 i 帧的 HOG 特征。
在识别出目标人的任务(或当前 VFOA)后,接下来,使用任务的相关上下文线索来识别注意力水平。对于每个任务,本文使用任务相关的 VFOA 跨度(T_s)来确定机器人应该等待多长时间或者机器人应该在怎样的时间周期内与目标人交互。此外,还定义了一些特定任务的线索来确定注意力的水平。以阅读 reading 为例,使用翻页率 P_t 和倾斜角度偏差来测量 LVFOA。而这些特定任务的线索的位置是根据人的身体的相对位置来确定的,本文应用的是文献 [7] 中给出的人体跟踪系统。
2.2 持续视觉注意力的集中程度
根据语境线索和注视模式,VFOA 水平分为低水平和高水平。当注意力水平降低时,系统假设检测到 VFOA 丢失。对于不同的任务,注意力水平检测如下:
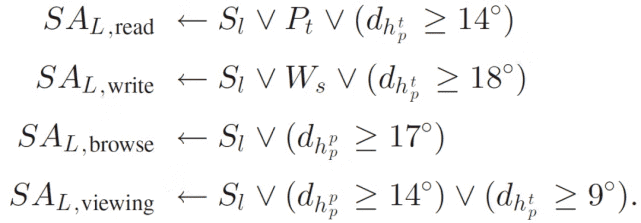
S_l 表示自发观看。如果检测到自发观看,则假定此人对某项任务没有特别注意,即,表示检测到低注意水平。对于阅读和写作任务,除了头部姿势的改变外,本文还考虑了「翻页」(Pt)和「停止写作」(Ws)等行为来检测低注意水平。对于上式来说,如果特定的头部姿势变化且稳定性大于或等于 3 帧,则相应任务的注意力水平较低。否则,表示注意力水平较高,当前的注意力集中在任务上。
2.3 注意力集中 / 转移的检测
焦点 / 注意力转移分为两个阶段。首先,为了吸引目标人的注意力,机器人从持续的 VFOA 中检测出焦点 / 转移的注意力。第二,在发送 AA 信号后,机器人需要检测到焦点 / 转移的注意力。
注意力从持续性 VFOA 转移:为了发起礼貌的社交互动,机器人应该根据目标人当前持续的 VFOA 去吸引他 / 她的注意力。在引起注意后,机器人检测到目标人移位的 VFOA。根据环境因素和目标人的心理焦点,持续性 VFOA 可分为五个区域之一:CFV、LNPFV、LFPFV、RNPFV 和 RFPFV。利用头部姿态的平移角度来检测移位的 VFOA 区域。
对机器人的注意力集中 / 转移:对机器人的注意力集中 / 转移的检测是机器人与目标人进行目光接触的重要线索。如果机器人和目标人没有面对面,那么机器人会发送一些 AA 信号,等待她 / 他的注意力朝向目标。当目标人转移注意力或将注意力转向机器人时,就要求机器人能够检测到对机器人的注意力集中 / 转移。为了进行成功的眼神交流,机器人将注意力集中 / 转移的程度分为三级:低、中、高。机器人向目标人发送一个 AA 信号,并逐帧分析输入的视频图像,以检测目标人是否正在向其移动。如果目标人正从她 / 他当前的注意力焦点转向机器人,那么在头部周围会检测到一些相邻的 h_m 窗口。聚焦 / 移位 VFOA 的级别按如下分析进行分类。
当除了头部运动之外没有检测到其他视觉线索时,可以假设集中 / 转移的注意力水平较低:
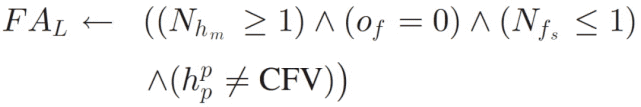
其中,N_hm 表示后续帧中出现连续的头部运动的窗口数量,o_f 表示是否检测到重叠窗口(检测到为(1),未检测到为(0)),(h_p)^ p 是头部姿势的估计平移角度,N_fs 是检测到重叠窗口后在后续帧中的面部稳定性检测结果。
如果在相邻的头部运动区域内通过重叠的面部窗口检测到头部运动,则注意力水平为中等:
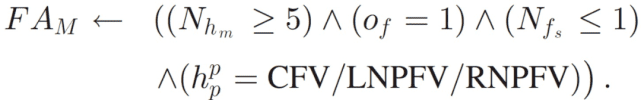
当成功检索到视觉线索并稳定下来时,注意力水平较高:
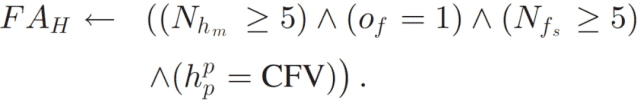
对应于上述三个公式,当能够满足公式右侧全部条件时,表示检测到对应的注意力水平。检测到的注意力水平将用于随后的意识生成,并进行成功的眼神交流。
2.4 基于视觉注意焦点的初始互动
在礼貌的社会交往中,人们通常会先抬起头来,或是转头朝着想与之交流的人,再进行后续的交流。然而,如果目标人对某项任务的注意力集中度很高,作为人类就会尝试使用一些更有力的动作(例如多次转头、挥手、走近对方并转头,使用声音等)来吸引对方的注意力。我们当然希望社交机器人也能做到这样。
在本文的研究中,机器人会监测目标人 VFOA 的程度及移位的 VFOA 区域,以选择适当的控制讯号。当持续性 VFOA 注意力水平较低且移位的 VFOA 位于 CFV/LNPFV/RNPFV 区域时,机器人会选择头部转向动作发出弱信号。当持续性 VFOA 注意力水平较低且移位的 VFOA 位于 LFPFV/RFPFV 区域时,机器人会使用摇头动作。在持续 VFOA 注意力水平较高且需要吸引目标人注意力的情况下,机器人还会采用摇头动作。
本文使用摇头动作作为一个很强的 AA 信号,因为物体的突然运动会引起人们的注意。如果一个人处于一个看不到机器人动作的位置,机器人的非语言行为所产生的视觉刺激不会影响到他 / 她。因此,本文不考虑移位的 VFOA 在 FOV 区域之外的情况。
2.5 建立沟通渠道
为了建立一个交流通道,机器人需要让目标人注意到它正看着她 / 他。机器人应该能够通过一些动作(例如面部表情、眨眼或点头)来表达它的这个意识。本文通过眨眼来产生这种意识,因为眨眼是形成一个人印象的最重要的线索之一。机器人通过完成眨眼的动作,能够使目标人感受到他 / 她正在被机器人注视。
如果机器人成功地吸引了目标人的注意,或者她 / 他注意到了机器人的动作,她 / 他就会将目光转向机器人。当她 / 他看着机器人的脸时,机器人能认出她 / 他的脸。在检测到目标人的面部稳定性后(即 FAH=1),机器人开始眨眼睛大约三次(1 blink/s),以建立一个通信通道。眨眼动作是通过快速关闭和打开 CG 图像的眼睑产生的,并通过 LED 投影仪显示在机器人的眼睛上。
3. 实验分析
本文在两个不同的机器人场景中验证所提出的方法。
3.1 静态机器人头部交互
本文在一个静态机器人的头部位置实现了基于目标人 VFOA 水平的人机交互场景。实验的目的是验证本文提出的交互系统会造成较少的干扰,并且在她 / 他参与某项任务时能够更成功地启动与目标人的交互。具体实验平台见图 5 所示。该系统包括头部检测与跟踪、态势识别、身体跟踪、人脸检测、眨眼、摇摄装置控制单元、VFOA 检测和转移 / 集中注意力检测模块。
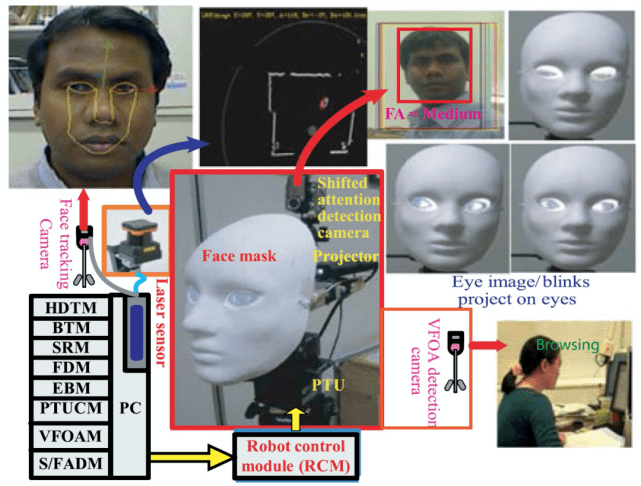
图 5. 静态机器人实验平台
参与者被要求注意自己的任务,并戴上带有音乐的耳机,以避免被机器人做出动作时所产生的声音干扰。本文用两个摄像机捕捉所有的互动。图 6(a)为实验环境。图 6(b)给出了本文系统应用于两种机器人行为的成功率。双尾 Z 比例检验(Z=3.837,p
3.2 博物馆场景中的 Robovie-R3
文章最后给出了另外一个实验,构建了一个位于博物馆内的参观者和机器人之间的交互场景。假设一个参观者在博物馆里观察画作,参观者会把注意力集中在某一幅画上。机器人位于远离画作的地方,因此,它不会干扰参观者的移动和注意力。当机器人检测到参观者的高水平注意力时,它会对参观者的头部方向进行分类,以选择机器人应该从哪一侧或哪个位置开始交互。机器人将参观者的头部定位分为五个角度区域:LFPFV、LNPFV、CFV、RNPFV 和 RFPFV。然后,机器人选择合适的运动路径和位置来启动交互(见图 7)。

图 7. 机器人的交互位置:(a)当在 LNPFV 区域检测到访客的注意方向时,机器人选择左侧的交互路径;(b) 当在 RNPFV 区域检测到访客的注意方向时,机器人选择右侧的交互路径。
将六幅画(P1–P6)挂在同一高度的墙上(见图 8(a))。这些画被放置在不同的地方,让参与者从一个固定的站立位置将 VFOA 固定在一幅特定的画上。一个 USB 摄像头(位于画作(P3)的顶部,用于检测访客的凝视和头部方向。P2、P3 和 P4 分别放置在 LNPFF、CFV 和 RNPFV 区域。将 Robovie-R3 眼睛(见图 8(b))替换为计算机图形生成的用于注视通信的投影眼睛(见图 8(c))。为了确认参观者能够与机器人进行眼神接触,在机器人头部下方放置了一个 USB 摄像头(见图 8(d))。在交互场景中,每个参与者被要求站在一个固定的位置,她 / 他的目光和头部方向可以在画作中自由的移动,最后,他 / 她会将注意力固定在图片 P2、P3 或 P4 上(见图 9)。

图 9. 实验场景的快照
实验中采用两种方法,方法 1(M1):机器人根据参观者的注意力方向选择运动路径,与参观者进行面对面交流;方法 2(M2):在 LNPFV 或 RNPFV 区域,机器人从参观者注意力方向的相反方向出现。实验要求参观者为每种方法填写一份问卷(在互动之后)。这项测量是一个利克特评分(Likert scale):1(强烈反对)到 7(强烈同意)。问卷有两个主观问题:问题 1(Q1):在互动开始时,你有没有感觉到你和机器人有眼神接触?问题 2(Q2):你认为机器人的方法对启动交互有效吗?
对于问卷 Q1(见表 1),当访问者观看图片 P2 时,两种方法(M1 和 M2)之间的差异具有统计学意义(Z=−2.831,p
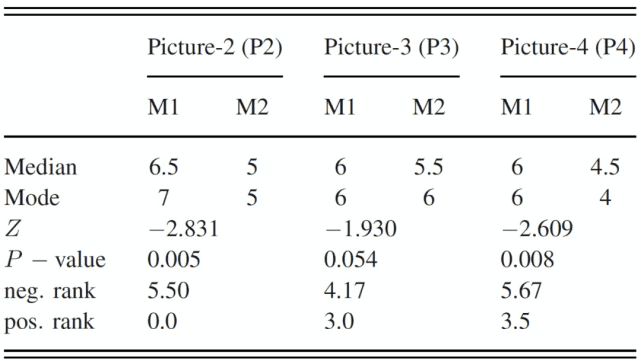
表 1. Q1 的问卷结果
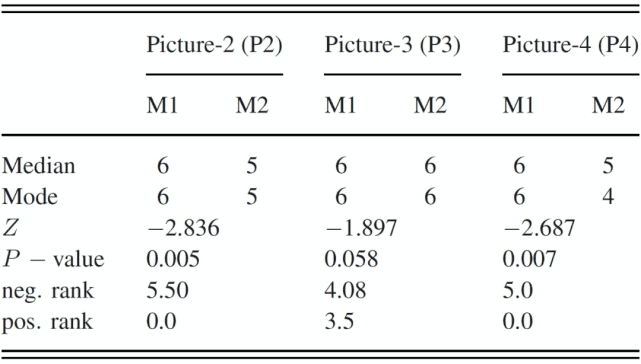
表 2. Q2 的问卷结果
对于问卷 Q2(见表 2),当参观者观看照片 P2 时,Wilcoxon 符号秩检验显示出显著差异(Z=−2.836 和 p
4. 文章小结
本文提出了一种智能的社交机器人工作方法,该方法从人机交互的注意力角度出发开发了一种机器人工作模式,它可以吸引目标人的注意力,并根据她 / 他的 LVFOA 与她 / 他建立一个交流渠道。该方法能够有效地启动与目标人的互动过程,吸引目标人的注意力,并建立与目标人的沟通渠道。
作者认为,当前的系统在实际应用中还存在以下问题:
首先,它需要环境中的摄像头来观察人们的注视模式。这在博物馆场景中是可以接受的。但是,在一些对环境声音有要求的场景下就无法应用。现在的机器人移动时会发出很大的噪音。如果它们移动,它们会引起人们的注意并中断他们的工作。在本文的实验中,要求参与者戴上带有音乐的耳机来减轻这些噪音的影响。然而,如果这种机器人能像人类一样安静地移动,它们可以移动到更容易用车载摄像头观察目标人的位置,则会具有更大的应用价值。
其次,本文使用了一个恒定值(T_s)作为持续 VFOA 的最大时间跨度。这是当人们没有表现出他们的低注意力水平或者机器人无法检测到他们的低注意力水平时,机器人将等待的最大时间跨度。在这之前,人们往往表现出较低的注意力水平。因此,如果我们把这个值设置得足够大,就像我们在实验中所做的那样,就不会有严重的问题。然而,如果能根据情况调整持续 VFOA 的最大时间跨度,实际应用效果会更好。
二、Predicting Engagement in Video Lectures

论文地址:https://arxiv.org/pdf/2006.00592.pdf
本文谈到的注意力也与上文不同,本文关注的是公开的教育资源(Open Educational Resources ,OERs))在线学习过程中学习者观看课程的注意力集中的程度。这里,「人机交互」指的是学员(人)与机器播放的课程(机)之间的交互情况。在在线学习场景中,一般认为能够使得学习者高度集中注意力的课程,是更为适合该学习者的课程。经典的 OERs 问题更关注个体用户(学习者)的参与度,而本文的目标是建立模型以找到情景无关的(即基于人群的)参与度特征,这是一个很少研究的问题。
在 OERs 问题中,学习者参与度是一个比受欢迎程度 / 浏览次数更可靠的衡量标准,比用户评分更为丰富,已经证明是衡量学习成果的关键组成部分,即:较好的参与度可以增加取得更好学习成果的可能性。本文作者深入探讨了建立基于人群的教育参与度预测模型。
1. 研究背景情况
随着在线学习平台的普及,越来越多的开放教育资源(OERs)面世。近年来大规模的教材创作对教育资源的自动管理提出了新的要求。在 OERs 的背景下,这意味着需要能够自动寻找和推荐符合学习者目标的材料,从而最大限度地提高学习效果。作者认为,实现上述目标主要有两个途径:情景化参与(Contextualised Engagement)和情景无关性参与(Context-Agnostic Engagement)。本文探讨的是后者,本文研究了情景无关性参与所涉及的特征。这将作为构建整合的教育推荐系统的第一步,为将情景化和情景无关的特征结合提供了可能。
由于相关的研究工作很少,为了在在线教育平台中部署研究模型,本文作者提出了以下研究问题:
RQ1:如何编码情景无关性参与?
RQ2:基于跨模态语言的特征对预测视频讲座的参与度有多有效?
RQ3:是否包含模态规范性功能能使性能显著改善?
RQ4:影响情景无关性参与的特点是什么?
RQ5:预测基于人群的参与比研究个性化参与更有用吗?
RQ6:我们能否假设一个共同的基础模型来预测不同知识领域的参与度?
在此基础上,本文完成了以下主要工作:
结合心理测量学文献,研究了重新定义用户参与信号的方法(RQ1)。
提出了两组易于自动化预测参与度的特征(基于情景无关的质量文献和视频特定特征的跨模式特征),并评估了它们(RQ2 和 RQ3)预测性能的差异。
构建了一个大型视频讲座数据集,并评估了所提出的参与信号和特征集(RQ2-4)的性能。
比较了跨模态特征,分析了单个特征在预测模型中的影响(RQ4)。
将本文的基于人群的参与方法与个性化的类似方法进行比较,以证明其有用性(RQ5)。
比较了将视频讲座分为两个不同的知识领域:STEM(如技术、物理和数学讲座)与其他领域(如艺术、社会科学和哲学讲座)的参与模式。
本文使用的数据来自一个流行的 OERs 资料库,视频讲座 Net(VLN),地址如下:www.videolectures.net,并从其中选择了研究人员在同行评审会议上演示的视频集合。
本文使用的特征包括:
授课时长(Lecture Duration),因为较短的视频一般更具吸引力;
分块(Chunking),即演讲是否被分成多个部分;
描述授课类型(Type of Lecture)的一组指标变量,如教程、研讨会等;
演讲者速度(Speaker Speed),使用每分钟平均讲词量来衡量;
沉默期率(Silence Period Rate,SPR),它是使用视频记录中表示沉默的特殊标记计算出来的。具体而言,SPR 计算如下:
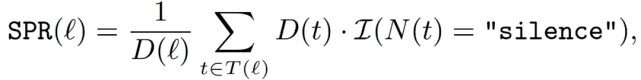
其中,t 是属于第 l 讲的标记 t (l) 集合中的标记,N 为标记 t 的类型,D 为标记 t 或讲座的持续时间,I () 是指示函数。
2. 具体任务分析
2.1 量化参与度(RQ1)
本文关注的参与度是一种隐性用户反馈。本文用来量化参与度的主要指标是标准化参与 / 观察时间(Median of Normalised Engagement/Watch Time,MNET)的中位数,MNET 被认为是参与教育材料的黄金标准 [8]。为了使 MNET 标签在 [0;1] 范围内,将 MNET 的上限设置为 1。作者在最初的数据分析中发现,VLN 数据集中的 MNET 值遵循对数正态分布,在这种分布中,大多数用户通常在较小的时间阈值后会放弃观看讲座。假设这可能是因为需要一些时间来决定内容是否与学习者相关。超过这个阈值的用户看起来更投入,因此离开率显著降低。为了解决这个问题本文使用 Log 变换来转换接合信号。最终标签,即对数中位数标准化参与时间(Log Median Normalised Engagement Time,LMNET)计算如下:
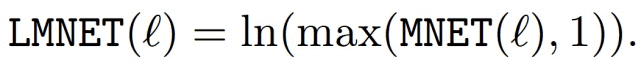
2.2 机器学习模型(RQ2)
为了学习根据参与度对视频讲座进行排名,本文使用逐点排序模型来评估效果。回归算法在实值空间中预测目标变量,这使得它们能够根据预测创建观测值的全局排名。此外,还使用了核函数评估了参与度预测的性能。引入核函数,能够有效捕获数据中的非线性特征。本文使用径向基函数(Radial Basis Function,RBF)。本文使用的回归算法包括岭回归(Ridge Regression,RR)和支持向量回归(Support Vector Regression ,SVR)。
此外,本文还评估了两种算法(常规算法、RBF 核)、核岭回归(KRR)和核支持向量回归(KSVR)的核化版本的性能。基于这些评估,能够了解模式中是否存在非线性特征,从而有利于完成预测任务。在上面讨论的所有四个模型中,本文使用标准缩放,因为这些模型并不是尺度不变的。L2 正则化用于防止过度拟合和多重共线性。由于在先前的工作中,基于集合技术的方法也表现良好,本文也使用随机森林回归(RF)方法来评估其预测能力。该模型还能够捕捉非线性模式。
2.3 特征重要性分析(RQ4)
本文使用 SHapley 加法解释(SHapley Additive exPlanations,SHAP)来进行特征重要性分析。SHAP 是一个模型无关的框架,它量化了特征对模型预测的影响。SHAP 通过为每个预测的每个特征计算一个形状值,估算了复杂模型族的特征重要性 [9]。通过将预测数据点的所有形状值绘制在形状摘要图中,可以确定每个特征对预测结果的影响。通过计算每个特征 f 的平均绝对形状(Mean Absolute SHAP,MAS)可以对特征影响进行定量分析。具体地,MAS 计算如下:
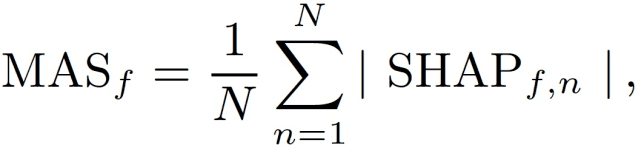
其中,N 是观察次数。
3. 实验分析
本文通过对两个特征集进行 5 次交叉验证来完成对不同机器学习模型的评估。不同机器学习模型在不同参与量化方法下的性能见表 1。添加视频特定功能时的性能见表 2。本文的实验是使用 scikitlearn、textatistic 和 SHAP 的 Python 包实现的。
Python 代码和所使用的数据库已公开:https://github.com/sahanbull/context-agnostic-engagement

表 1. 基于 5 倍交叉验证和交叉模态特征的具有标准误差的参与预测模型的成对精度(Pair.)和 Spearman 秩相关系数(SROCC)
3.1 RQ1 任务实验结果:分析参与度、浏览次数和平均星级评分之间的关系
本文所使用的 VLN 数据源中也有考虑不同的讲座课程内容子集的平均星级评分(显式反馈)。值得注意的是,我们只能获得平均星级评级,而不是每个观察员的个人评级或测量数量。图 1 中给出了平均星级 vs MNET 的结果和浏览次数。SROCC 接近于零,这主要是因为讲座数量多、收视率高,但参与度低,而且观看人数也不多。作者测试了所考虑的 4 个不同版本的参与度(原始版本、清洁版本、标准化版本和比较版本)的相关性,但都取得了相似的结果,SROCC 接近于零。作者从图 1 得出结论:浏览量、评分和参与度确实代表了非常不同的信息。
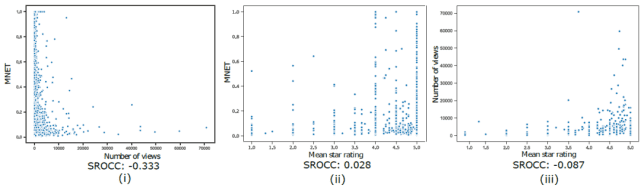
图 1. 散点图,显示了(i)浏览量与 MNET 之间的关系,(ii)视频讲座的平均星级与 MNET 之间的关系,(iii)平均星级与浏览量之间的关系,以及 Spearman 的等级相关系数(SROCC)。
3.2 RQ1-2 任务实验结果:测试不同机器学习模型和参与信号的交叉模态特征
作者提出了四种比较精确的定量方法(原始版本 LMNET、 清洁版本、标准化版本和比较版本),并对这四种方法进行了比较。这个实验的目的是验证在给定所提出特征的前提下,哪个输出目标变量更容易预测。表 2 给出了这些结果,以及在基于 5 倍交叉验证的标准误差界下,每个机器学习模型获得的成对精度(Pair.)和 Spearman 秩序相关系数(SROCC)。精度值越大,模型的性能越好。这些结果表明,原始 LMNET 可能是最合适的目标标签,特别是在建立预测原始 LMNET 的模型时,所提出的特征似乎更有用。
作者从表 2 中得出另外一个观察结论是:KRR 和 KSVR 模型的性能优于线性模型。这表明,数据集中可能存在非线性的关系,而引入核函数可以更好地捕捉到这些非线性特征。

表 2. 通过使用基于内容的功能与基于内容的 + 视频特定功能的 RF 模型的 5 倍交叉验证,实现标准误差的成对准确度。
3.3 RQ3 任务实验结果:研究情态特征对跨学科领域的影响和比较
表 3 的结果用于验证:当仅限于特定主题的比较(属于同一主题领域的讲座对)时,如何提高成对准确度。在多数情况下,教育推荐系统需要在属于同一主题领域的一组资源中进行选择。表 3 还显示了在专门使用跨模态功能集和添加视频规范化功能时性能的差异。添加视频功能可使性能提高约 2%。这一结果表明,虽然可以在不同的实际场景中复用特征提取器,但当处理跨模态的特征时,性能就会受到影响。

表 3. 通过使用基于内容的功能与基于内容的 + 视频规范功能的射频模型的 5 倍交叉验证,实现标准误差的成对准确度。
3.4 RQ4 任务实验结果:研究与材料长度有关的参与度分布
在这一小节的实验中,作者重点研究讲座的长度如何影响参与度预测。首先,作者给出了视频讲座中总字数的分布(图 3),这与讲座视频的长度直接相关。根据观察到的多模态分布,作者将讲座视频分为两组,少于 5000 字的短讲座和长讲座(见图 4 中的参与度分布)。作者认为,对于长时间的讲座,观看时间的百分比往往较短。图 4 中的 MNET 分布表明,与短讲座相比,长讲座的目标值分布更偏向于 0,这表明学习者较不倾向于观看长视频片段。这很可能是由其它一些超出了可测量特征范围的因素造成的,例如有限时间长度内的可用性和学习者的注意力持续时间短等。
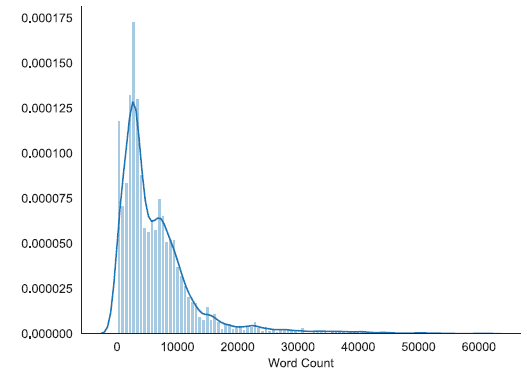
图 3. 视频讲座字数分布
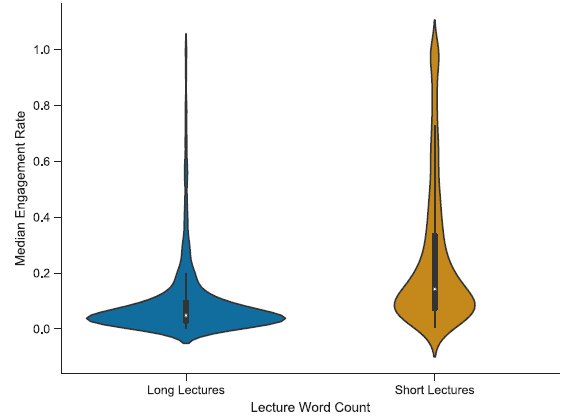
图 4. 短期和长期讲座的参与标签分布
4. 文章小结
这篇文章聚焦的是一个较少提及的研究领域,作者提出了一个情境无关的参与预测模型,该模型有助于改善教育推荐系统的效果。在不断推出在线学习内容的情况下,所提出的预测模型估计了将这些学习内容展示给学习者的吸引力,即这些学习内容将如何影响学习者的注意力。通过使用这个模型可以更好地平衡与学习者满意度相关的风险和获取有效的新学习内容的机会。此外,本文提出的情景无关的模型可以以不同的方式与其它应用于在线学习的个性化系统集成。
作者提出,为了进一步改进模型,未来的工作主要关注三个问题:
1)包含更复杂的特性。向模型中引入更为复杂的特征,例如权威性(Authority)和主题覆盖率(Topic Coverage)等,可能能够进一步改进模型的效果。
2)在跨模态方面,可以考虑更多关注基于内容理解的特征,如话题连贯性和论据强度等。在特定的视频前端,甚至可以融合主持人的生动性、音质和叙事品质等特征。
3)关于模型的泛化能力,可以使用更大的视频讲座数据集和文本数据集评估跨模态特征集的有效性,从而提高特征集的可信度。同样,也应进一步考虑使用非英语语言的数据集。
三、Developing Joint Attention for Children with Autism in Robot-Enhanced Therapy

论文地址:https://link.springer.com/article/10.1007/s12369-017-0457-0
本文讨论的是社交机器人的一个医疗类的应用,即对于患有自闭症(Autism Spectrum Disorder,ASD)的孩子提供机器人辅助的增强治疗。造成自闭症的主要心理因素之一是缺乏与互动伙伴的共同注意力(Joint Attention,JA)。社交机器人在自闭症儿童的干预中具有重要的应用价值,尤其是在针对诸如共同注意力 JA 等技能时。之前关于儿童自闭症的研究显示,自闭症儿童在接受机器人互动训练后确实能够改善他们的 JA 表现。基于这一研究结论,本文作者认为,在机器人辅助下实施的干预措施有可能成为有效的 ASD 儿童 JA 技能训练和干预的措施。
因此,本文的主要研究目的是探讨自闭症儿童的 JA 表现是否依赖于机器人在治疗过程中使用的社交线索(Social Cues)。本文主要考虑了三种不同类型的社交线索:头部方向(head orientation),指示( pointing)和口头指令( vocal instruction)。作者认为,机器人使用的社交线索越多,儿童的表现就会越好。此外,本文利用了欧盟 Dream 项目(https://www.dream2020.eu/)开发的 NAO 机器人,研究了机器人强化治疗与标准人类治疗是否具有相似的模式。
1. 研究内容介绍
共有 11 名儿童参与了这项研究,但只有 5 名儿童符合纳入标准,即:(1)基于 DSM-5 的自闭症诊断,(2)根据自闭症诊断观察量表(ADOS)进行诊断确认的,(3)在执行目标行为方面存在明显的困难的。所有的儿童都是从自闭症特兰西瓦尼亚协会(Cluj Napoca,罗马尼亚)招募的,这是一个为自闭症儿童提供专门服务的中心。参与测试的儿童的资料见表 1。
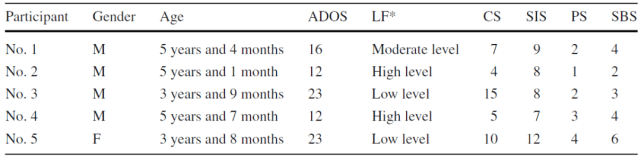
表 1. 受试者情况描述
本文的实验采用了经典的单病例替代治疗设计 [10]。单病例替代治疗设计可以为治疗手段的干预效果提供严格的实验评估,以及具有以下几个基本特点:(1)确定基线测量值;(2)连续和重复测量依赖变量;(3) 独立变量操作;(4)针对同一受试者随时间复制干预效果。单病例替代治疗设计提供了对一个受试者比较两种治疗方案的可能性。因此,在一个基线时期内,两个治疗方案(A 和 B)以交替(随机)顺序进行,从而完成对一个或多个行为影响的观察。分别绘制出每种干预措施的效果数据,以给出每种治疗效果的直观表示。
在受试的各个阶段,儿童都直接与机器人 / 人类互动。在机器人增强治疗(robot-enhanced treatment,RET)条件下,机器人坐在桌子上,而基线测量(baseline measurement,BM)和标准人类治疗(standard human treatment,SHT)条件下,治疗师坐在桌子后面的椅子上,具体见图 1。

图 1. 实验环境:儿童、互动伙伴(机器人 / 人类)和调解人
在房间的右侧,操作员使用「Wizard of Oz」范式控制机器人的动作。在所有的任务中,都有调解人作为第三者参与交互,他的任务是在参与交互的伙伴(机器人或人类)和孩子之间进行协调以及提供必要的提示。摄像机和传感器放置在实验室机器人后面的位置,以捕捉孩子与机器人 / 人类互动时的面部表情、凝视和动作。
「Wizard of Oz」机器人实验,意思是受试者与被认为是自主的计算机系统进行交互,但实际上是由看不见的人操作或部分操作。
本文按照离散实验的方式完成任务,这是自闭症早期干预计划中常用的方法。这种方法主要针对训练几种技能以及在这几种技能的基础上随后教授更复杂的行为。这种方法的特点是:教学环境是高度结构化的,行为被分解成离散的子技能,并以多次、连续的实验方式来呈现;通过明确的提示,教孩子对伙伴所发出的辨别性刺激做出反应。
按照单例实验设计,每个孩子都会经历以下的实验场景。
基线测量(BM),大约 6 到 8 次测量,直到达到一个稳定的基线水平。
机器人强化治疗(RET),约 8 个疗程。
标准人治疗(SHT),约 8 个疗程。
RET 或 SHT,具体取决于哪种治疗方法对孩子的效果更好,大约 4 次治疗。
每个疗程持续约 10 分钟,每天都会重复进行这些疗程。RET 和 SHT 之间的顺序是随机的,以避免在实验中出现顺序效应。基线的疗程是在与治疗师的互动中进行的,这部分实验满足了离散实验的要求。对孩子进行测试,在没有明确的提示、提示消退或后援的情况下,验证他们是否会对伙伴发出的辨别性刺激做出反应。JA 任务的结构包括:指示(instruction)、反应(response)和结果(consequence),具体见表 2。

表 2. JA 任务结构
实验中所产生的的所有变量均使用用于对行为动作编码的 Elan - 语言注释器(4.5 版)进行人工编码 [10]。变量只在任务过程中进行评估,而不需要在介绍或演示阶段进行评估。对于儿童对指令的反映情况,依照表 3 中给出的行为网格进行评估。

表 3. 评估 JA 表现的行为网格
本研究使用的是由 Softbank Robotics 开发的人形机器人 NAO [11]。NAO 高 58 厘米,重量为 5 公斤,运动自由度为 25 度。它配备了丰富的传感器阵列,2 个摄像头,4 个麦克风,声纳测距仪、2 个红外发射器和接收器、1 个惯性板、9 个测距仪,以及触觉传感器和 8 个压力传感器。NAO 的设备还包括 LED 灯、两个扬声器以及具有特定语言的语调和语速的语音合成器。
为了分析数据,本文使用了一个综合非参数测试(Friedman)比较了每种类型会话(BM、SHT、RET)在三种提示条件(看、看 + 指示、看 + 指示 + 口头指令)下的表现。与第一篇文章类似,本文也使用 Wilcoxon 符号秩检验进行两两比较,以确定产生具有统计学意义的性能差异的条件。最后,本文还计算了一个参数效应大小指标(Cohen\'s d),以量化这些条件之间的差异。
2. 实验分析
作者在原文中,分别给出了参与受试的 5 名儿童的实验结果,我们在这篇文章中以第一名儿童的结果作为示例进行分析。对于这名儿童,BM 中的综合非参数(Friedman)检验显示在三种提示条件之间存在显著差异,chi^2(2)=14.77,p=.001。随后,采用 Wilcoxon 符号秩检验对这一效应进行了两两比较,结果表明,头部定向(head orientation)比指示方法(pointing)得分低,Z=−2.56,p=.011,Cohen d=−4.55,而得分最低的是指示(pointing)+ 口头指令(vocal instruction),Z=−2.59,p=.010,d=-4.55。指示(pointing)与指示(pointing)+ 口头指令(vocal instruction)的方法之间无显著性差异,p>0.05。
SHT 的结果也相似,综合非参数(Friedman)检验显示三种类型的提示有显著差异,chi^2(2)=15.08,p=.001。两两比较表明,头部定向(head orientation)情况下的得分明显低于指示方法(pointing),Z=−2.60,p=.009,d=−9.22,以及指示(pointing)+ 口头指令(vocal instruction),Z=−2.59,p=.010,d=−4.68。指示(pointing)与指示(pointing)+ 口头指令(vocal instruction)之间无显著性差异,p>0.05。
此外,RET 也给出了类似的实验结果,综合非参数(Friedman)检验显示三种类型的提示有显著差异,chi^2(2)=7.53,p=.023。头部定向的得分低于指示方法,Z=-2.53,p=.012,d=-2.59,而指示 + 口头指令,Z=-2.38,p=.017,d=-3.71。在 RET 条件下,指示与指示 + 口头指令的方法比较无显著性差异(p>0.05)。
图 2 给出了这个参与者的实验结果,而表 4 给出了针对该实验结果的统计分析。
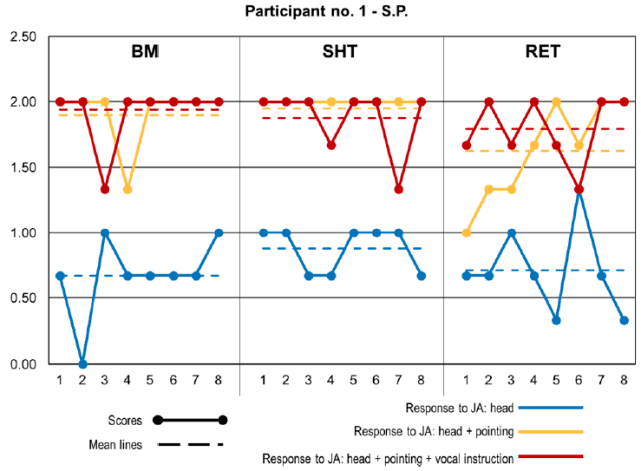
图 2. 第 1 名参与者在激励类型和会话类型上的 JA 表现(X 轴表示受试者在 JA 任务中得到的分数;Y 轴表示会话数)。
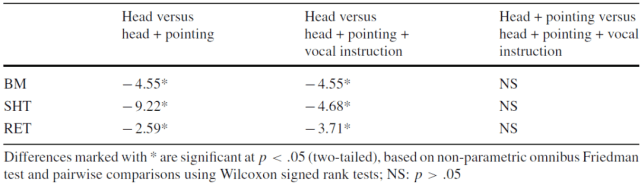
表 4. 第一位受试者接受不同指令后的综合结果和效果大小对比(Cohen\'s d)。
3. 文章小结
在针对 ASD 儿童的治疗中,有很多种不同的方法都可以用于定义儿童和社交机器人之间的互动 [12],本文主要使用的是 JA 相关的任务,即儿童参与到任务中并在整个会话过程中保持对解决问题的注意力。
本文给出了一个详细的实验并对结果进行了分析。本文的研究结果表明,指示(pointing)是 ASD 儿童参与 JA 活动的一个重要线索,因此,指示(pointing)可以用于改进自闭症儿童 JA 技能的机器人增强干预。作者认为,由本文的研究结论可以推断,机器人的互动遵循着与人类互动相似的模式,而指示(pointing)是吸引自闭症儿童的关键因素。
四、本文小结
本文关注了人机交互中的注意力问题,结合在社交机器人中的应用,具体探讨如何通过注意力的方式建立人和机器之间的沟通渠道,以改进机器 / 机器人与人类的交互效果。
本文详细介绍了一篇根据视觉注意力焦点来吸引和控制目标人注意力的技术分析文章,此外还介绍了两个实践中的应用,一是在线教育效果评估,另外一个是针对自闭症儿童的机器人辅助治疗。
近两年,社交机器人的研究及应用逐渐退火,研究层面对类似问题的关注也逐渐减少。如何令机器人真正像人一样思考和交流,关注「注意力」也许是一个很好的切入点。
参考文献
[1] Stiefelhagen, R Waibel, A, Modeling focus of attention for meeting indexing based on multiple cues,IEEE TRANSACTIONS ON NEURAL NETWORKS,2002,https://www.onacademic.com/detail/journal_1000011496569999_01e2.html
[2] M. Hayhoe and D. Ballard, “Eye movements in natural behavior,” Trends Cognitive Sci., vol. 9, no. 4, pp. 188–194, 2005.
[3] F. Tarr´es, (2013, Mar.). “GTAV face database.” [Online]. Available: http://gps-tsc.upc.es/ GTAV/ ResearchAreas /UPCFaceDatabase /GTAVF aceDatabase.htm
[4] S. S. Beauchemin and J. L. Barron, “The computation of optical flow,” ACM Comput. Surv., vol. 27, no. 3, pp. 433–467, 1995.
[5] P. A. Viola and M. J. Jones, “Robust real-time face detection,” Int. J. Comput. Vision, vol. 57, no. 2, pp. 137–154, 2004.
[6] N. Dalal and B. Triggs, “Histograms of oriented gradients for human detection,” in Proc. IEEE Comput. Soc. Conf. Comput. Vision Pattern Recog., 2005, pp. 886–893.
[7] Y. Kobayashi and Y. Kuno, “People tracking using integrated sensors for human robot interaction,” in Proc. IEEE Int. Conf. Ind. Technol., Ann Arbor, MI, USA, Mar. 14–17, 2010, pp. 1597–1602.
[8] P. J. Guo, J. Kim, and R. Rubin. How video production affects student engagement: An empirical
study of mooc videos. In Proc. of the First ACM Conf. on Learning @ Scale, 2014.
[9] S. M. Lundberg and S.-I. Lee. A unied approach to interpreting model predictions. In Advances in Neural
Information Processing Systems. 2017.
[9] Barlow DH, Hayes SC (1979) Alternating treatments design: one strategy for comparing the effects of two treatments in a single subject. J Appl Behav Anal 12(2):199–210
[10] Lausberg H, Sloetjes H (2009) Coding gestural behavior with the NEUROGES-ELAN system. Behav Res Methods 41(3):841–849
[11] Gouaillier D, Hugel V, Blazevic P, Kilner C, Monceaux J, Lafourcade P, Maisonnier B (2009) Mechatronic design of NAO humanoid. In: Robotics and automation, 2009. ICRA’09. IEEE international conference on 769–774. IEEE
[12] Anzalone SM, Boucenna S, Ivaldi S, ChetouaniM(2015) Evaluating the engagement with social robots. Int J Soc Robot 7(4):465–478
分析师介绍:
本文作者为仵冀颖,工学博士,毕业于北京交通大学,曾分别于香港中文大学和香港科技大学担任助理研究员和研究助理,现从事电子政务领域信息化新技术研究工作。主要研究方向为模式识别、计算机视觉,爱好科研,希望能保持学习、不断进步。
关于机器之心全球分析师网络 Synced Global Analyst Network
机器之心全球分析师网络是由机器之心发起的全球性人工智能专业知识共享网络。在过去的四年里,已有数百名来自全球各地的 AI 领域专业学生学者、工程专家、业务专家,利用自己的学业工作之余的闲暇时间,通过线上分享、专栏解读、知识库构建、报告发布、评测及项目咨询等形式与全球 AI 社区共享自己的研究思路、工程经验及行业洞察等专业知识,并从中获得了自身的能力成长、经验积累及职业发展。
相关推荐
-
DNF驭剑士(dnf驭剑士堆什么属性)


作者:人见_DNF开服的16年以来,一直在不断推出新的职业,如今不知不觉已经有62个之多了。所有的职业都具有各自的特色与优缺点,但因为职业种类太多,除非是自己养的大号,很难了解其他职业的什么是强项、什么是弱点。因此DNFChosun分别为各个职业制作了6项主要能力值一目了然、能够间接了解职业性能的图
-
奇迹暖暖童话梦乡(奇迹暖暖童话香氛)
[闽南网]奇迹暖暖童话梦乡活动中,玩家可获得真爱魔法套装。奇迹暖暖真爱魔法顶配有哪些?小编艾米分享下奇迹暖暖真爱魔法套装顶配高配关卡分析。奇迹暖暖真爱魔法顶配有哪些?真爱魔法套装顶配高配关卡分析:发型:熏然梦寐连衣裙:情衷魔药联盟高配:1-7(第2)关卡顶配:13-7关卡高配:6-1(第5), 10
-
火炬之光2宠物选哪个(火炬之光2哪个宠物厉害)

继荣耀斗技场和新剧情关卡玩法曝光后,各位冒险家翘首期盼的《火炬之光》移动版新资料片“巅峰对决”,将在今日揭秘宠物觉醒系统,宠物外形大优化,超强资质增益!对于即将到来的宠物觉醒系统,大家是否对10月25日的《火炬之光》移动版新资料片有了更多期待呢?宠物觉醒 外观优化实力大提升在《火炬之光》移动版中,宠
-
红色警戒可以开挂吗(红色警戒开挂指令)



大家好,我是X博士。“是否要在游戏中加入机器人”这个话题,一直以来都是《绝地求生》所面临的一大艰难抉择,也是在玩家中讨论最多的问题。尤其是在近两年玩家数量有所下滑,这个问题便也显得更为关键。作为游戏厂商来说,加入新手机器人无疑会让游戏上手难度下降,这对吸引新玩家来说绝对是一件好事。可老玩家大多数都会
-
dnf套装自选礼盒(dnf传说装备自选礼盒怎么选)




从上一年开始,细心的玩家发现,“结婚”类型的活动,突然就戛然而止,心意通道具也不送了!没了心意通道具,要弄结婚属性,就变得难起来。鉴于玩家呼声较高,对心意通道具的需求,结婚活动千呼万唤始出来,还白送绝版限定装扮!“结婚”活动来了!白送绝版限定装扮在2.10版本中,以“甜蜜传讯,为爱充电”为主题,推出

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请通知我们,一经查实,本站将立刻删除。