
.jpg)
目录
案例准备
案例分析
启动项目
模拟访问并观察丢包情况
3s 的 RTT -很可能是因为丢包后重传导致的
链路层(ethtool 或者 netstat)
网络层和传输层
所谓丢包,是指在网络数据的收发过程中,由于种种原因,数据包还没传输到应用程序中,就被丢弃了。这些被丢弃包的数量,除以总的传输包数,也就是我们常说的丢包率。丢包率是网络性能中最核心的指标之一。
丢包通常会带来严重的性能下降,特别是对 TCP 来说,丢包通常意味着网络拥塞和重传,进而还会导致网络延迟增大、吞吐降低。
案例准备
今天的案例需要用到两台虚拟机。
使用vagrant拉起两台虚机。
- 机器配置:2 CPU,2GB 内存。
- 预先安装 docker、curl、hping3 等工具
案例分析
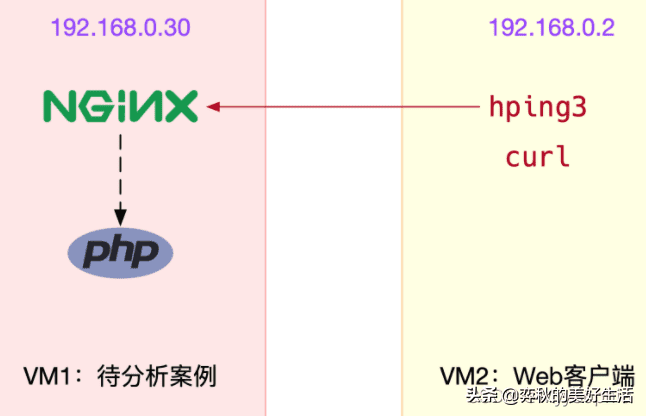
我们今天要分析的案例是一个 Nginx 应用,如下图所示,hping3 和 curl 是 Nginx 的客户端。
我这里对应的ip是192.168.56.10 和192.168.56.11

启动项目
[root@hadoop100 /opt]#docker run --name nginx --hostname nginx --privileged -p 80:80 -itd feisky/nginx:drop
Unable to find image \'feisky/nginx:drop\' locally
drop: Pulling from feisky/nginx
6ae821421a7d: Pull complete
da4474e5966c: Pull complete
eb2aec2b9c9f: Pull complete
c6797838e67f: Pull complete
d61fc363525d: Pull complete
Digest: sha256:c16b8286464e50b4c9704ed83e3e111f9c19a60f4ceca775d752b4bd0108637f
Status: Downloaded newer image for feisky/nginx:drop
5867df6e997b047bf995ade980f0db0206bec2df1d9e8738bef415c55c55bb71
You have mail in /var/spool/mail/root
[root@hadoop100 /opt]#
[root@hadoop100 /opt]#
[root@hadoop100 /opt]#docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
5867df6e997b feisky/nginx:drop "/start.sh" 43 seconds ago Up 42 seconds 0.0.0.0:80->80/tcp, :::80->80/tcp nginx

模拟访问并观察丢包情况
我们切换到终端二中,执行下面的 hping3 命令,进一步验证 Nginx 是不是真的可以正常访问了。注意,这里我没有使用 ping,是因为 ping 基于 ICMP 协议,而 Nginx 使用的是 TCP 协议。
- -c 表示发送 20 个请求
- -S 表示使用 TCP SYN
- -p 指定端口为 80
[root@hadoop101 yum.repos.d]# hping3 -c 20 -S -p 80 192.168.56.10
HPING 192.168.56.10 (eth1 192.168.56.10): S set, 40 headers + 0 data bytes
len=46 ip=192.168.56.10 ttl=63 DF id=0 sport=80 flags=SA seq=1 win=5120 rtt=1201.8 ms
len=46 ip=192.168.56.10 ttl=63 DF id=0 sport=80 flags=SA seq=4 win=5120 rtt=1.9 ms
DUP! len=46 ip=192.168.56.10 ttl=63 DF id=0 sport=80 flags=SA seq=4 win=5120 rtt=1002.7 ms
len=46 ip=192.168.56.10 ttl=63 DF id=0 sport=80 flags=SA seq=5 win=5120 rtt=1.4 ms
len=46 ip=192.168.56.10 ttl=63 DF id=0 sport=80 flags=SA seq=9 win=5120 rtt=0.9 ms
len=46 ip=192.168.56.10 ttl=63 DF id=0 sport=80 flags=SA seq=10 win=5120 rtt=0.8 ms
len=46 ip=192.168.56.10 ttl=63 DF id=0 sport=80 flags=SA seq=11 win=5120 rtt=0.8 ms
len=46 ip=192.168.56.10 ttl=63 DF id=0 sport=80 flags=SA seq=12 win=5120 rtt=1.9 ms
len=46 ip=192.168.56.10 ttl=63 DF id=0 sport=80 flags=SA seq=13 win=5120 rtt=0.9 ms
DUP! len=46 ip=192.168.56.10 ttl=63 DF id=0 sport=80 flags=SA seq=10 win=5120 rtt=3204.2 ms
--- 192.168.56.10 hping statistic ---
20 packets transmitted, 10 packets received, 50% packet loss
round-trip min/avg/max = 0.8/541.7/3204.2 ms

从 hping3 的输出中,我们可以发现,发送了 20 个请求包,却只收到了 10 个回复,50% 的包都丢了。再观察每个请求的 RTT 可以发现,RTT 也有非常大的波动变化,小的时候只有 1ms,而大的时候则有 3s。
3s 的 RTT -很可能是因为丢包后重传导致的
根据这些输出,我们基本能判断,已经发生了丢包现象。可以猜测,3s 的 RTT ,很可能是因为丢包后重传导致的。那到底是哪里发生了丢包呢?
排查之前,我们可以回忆一下 Linux 的网络收发流程,先从理论上分析,哪里有可能会发生丢包。你不妨拿出手边的笔和纸,边回忆边在纸上梳理,思考清楚再继续下面的内容。
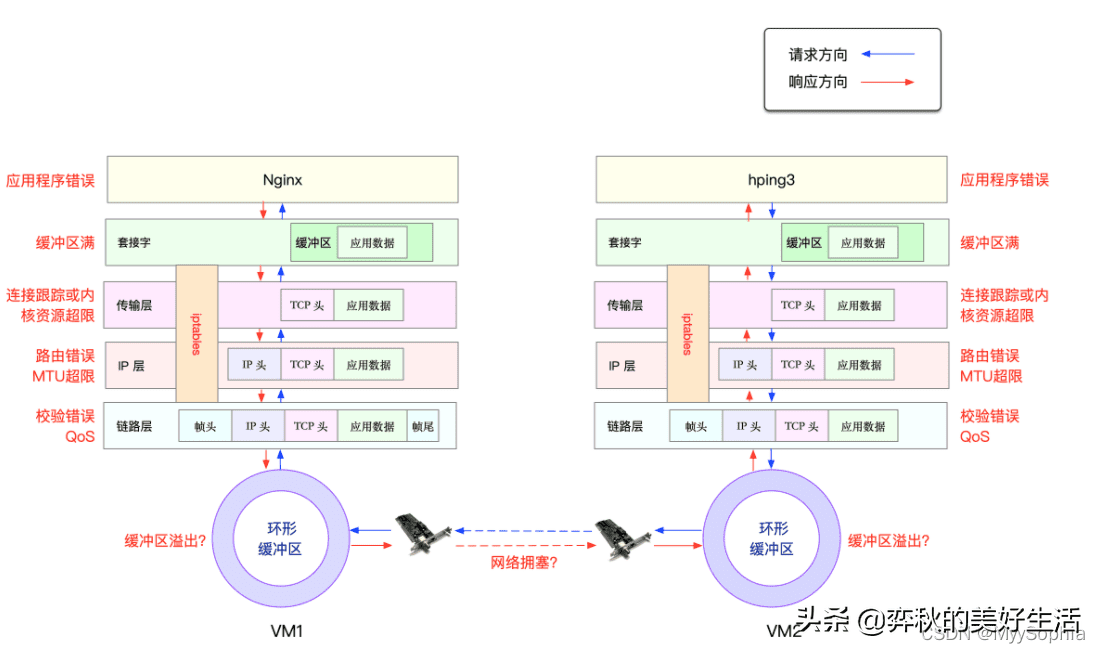

从图中你可以看出,可能发生丢包的位置,实际上贯穿了整个网络协议栈。换句话说,全程都有丢包的可能。比如我们从下往上看:
- 在两台 VM 连接之间,可能会发生传输失败的错误,比如网络拥塞、线路错误等;
- 在网卡收包后,环形缓冲区可能会因为溢出而丢包;
- 在链路层,可能会因为网络帧校验失败、QoS 等而丢包;
- 在 IP 层,可能会因为路由失败、组包大小超过 MTU 等而丢包;
- 在传输层,可能会因为端口未监听、资源占用超过内核限制等而丢包;
- 在套接字层,可能会因为套接字缓冲区溢出而丢包;
- 在应用层,可能会因为应用程序异常而丢包;
- 此外,如果配置了 iptables 规则,这些网络包也可能因为 iptables 过滤规则而丢包。
当然,上面这些问题,还有可能同时发生在通信的两台机器中。不过,由于我们没对 VM2 做任何修改,并且 VM2 也只运行了一个最简单的 hping3 命令,这儿不妨假设它是没有问题的。
为了简化整个排查过程,我们还可以进一步假设, VM1 的网络和内核配置也没问题。这样一来,有可能发生问题的位置,就都在容器内部了。
现在我们切换回终端一,执行下面的命令,进入容器的终端中:
链路层(ethtool 或者 netstat)
首先,来看最底下的链路层。当缓冲区溢出等原因导致网卡丢包时,Linux 会在网卡收发数据的统计信息中,记录下收发错误的次数。
你可以通过 ethtool 或者 netstat ,来查看网卡的丢包记录。
[root@hadoop100 /usr/local/src/sysstat-11.5.5]#docker exec -it nginx bash
root@nginx:/#
root@nginx:/#
root@nginx:/# netstat -i
Kernel Interface table
Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
eth0 100 58 0 0 0 19 0 0 0 BMRU
lo 65536 0 0 0 0 0 0 0 0 LRU

输出中的 RX-OK、RX-ERR、RX-DRP、RX-OVR ,分别表示接收时的总包数、总错误数、进入 Ring Buffer 后因其他原因(如内存不足)导致的丢包数以及 Ring Buffer 溢出导致的丢包数。
TX-OK、TX-ERR、TX-DRP、TX-OVR 也代表类似的含义,只不过是指发送时对应的各个指标。
注意,由于 Docker 容器的虚拟网卡,实际上是一对 veth pair,一端接入容器中用作 eth0,另一端在主机中接入 docker0 网桥中。veth 驱动并没有实现网络统计的功能,所以使用 ethtool -S 命令,无法得到网卡收发数据的汇总信息。
从这个输出中,我们没有发现任何错误,说明容器的虚拟网卡没有丢包。不过要注意,如果用 tc 等工具配置了 QoS,那么 tc 规则导致的丢包,就不会包含在网卡的统计信息中。
所以接下来,我们还要检查一下 eth0 上是否配置了 tc (traffic control)规则,并查看有没有丢包。我们继续容器终端中,执行下面的 tc 命令,不过这次注意添加 -s 选项,以输出统计信息:
root@nginx:/#
root@nginx:/#
root@nginx:/# tc -s qdisc show dev eth0
qdisc netem 8001: root refcnt 2 limit 1000 loss 30%
Sent 1038 bytes 19 pkt (dropped 7, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
root@nginx:/#

什么是tc?
从 tc 的输出中可以看到, eth0 上面配置了一个网络模拟排队规则(qdisc netem),并且配置了丢包率为 30%(loss 30%)。
再看后面的统计信息,发送了 19个包,但是丢了 7 个。
看来,应该就是这里,导致 Nginx 回复的响应包,被 netem 模块给丢了。
既然发现了问题,解决方法也就很简单了,直接删掉 netem 模块就可以了。我们可以继续在容器终端中,执行下面的命令,删除 tc 中的 netem 模块:
#注意是容器内部
root@nginx:/# tc qdisc del dev eth0 root netem loss 30%
root@nginx:/#
root@nginx:/#
root@nginx:/# tc -s qdisc show dev eth0
qdisc noqueue 0: root refcnt 2
Sent 0 bytes 0 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
root@nginx:/#

重新执行刚才的 hping3 命令
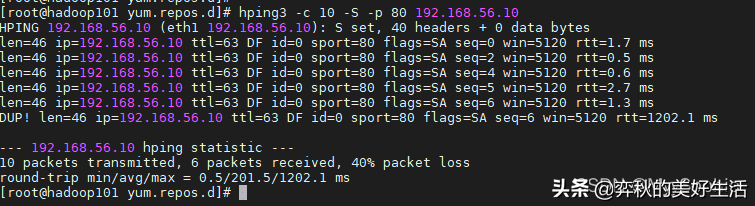

从 hping3 的输出中,我们可以看到,跟前面现象一样,还是 40% 的丢包;RTT 的波动也仍旧很大,从 3ms 到 1s。
显然,问题还是没解决,丢包还在继续发生。不过,既然链路层已经排查完了,我们就继续向上层分析,看看网络层和传输层有没有问题。
网络层和传输层
我们知道,在网络层和传输层中,引发丢包的因素非常多。不过,其实想确认是否丢包,是非常简单的事,因为 Linux 已经为我们提供了各个协议的收发汇总情况。
我们继续在容器终端中,执行下面的 netstat -s 命令,就可以看到协议的收发汇总,以及错误信息了:
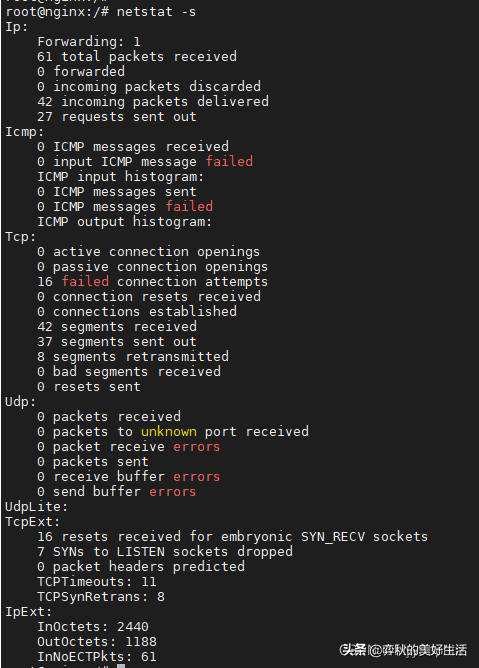
root@nginx:/# netstat -s
Ip:
Forwarding: 1 // 开启转发
31 total packets received // 总收包数
0 forwarded // 转发包数
0 incoming packets discarded // 接收丢包数
25 incoming packets delivered // 接收的数据包数
15 requests sent out // 发出的数据包数
Icmp:
0 ICMP messages received // 收到的 ICMP 包数
0 input ICMP message failed // 收到 ICMP 失败数
ICMP input histogram:
0 ICMP messages sent //ICMP 发送数
0 ICMP messages failed //ICMP 失败数
ICMP output histogram:
Tcp:
0 active connection openings // 主动连接数
0 passive connection openings // 被动连接数
11 failed connection attempts // 失败连接尝试数
0 connection resets received // 接收的连接重置数
0 connections established // 建立连接数
25 segments received // 已接收报文数
21 segments sent out // 已发送报文数
4 segments retransmitted // 重传报文数
0 bad segments received // 错误报文数
0 resets sent // 发出的连接重置数
Udp:
0 packets received
...
TcpExt:
11 resets received for embryonic SYN_RECV sockets // 半连接重置数
0 packet headers predicted
TCPTimeouts: 7 // 超时数
TCPSynRetrans: 4 //SYN 重传数
...
netstat 汇总了 IP、ICMP、TCP、UDP 等各种协议的收发统计信息。不过,我们的目的是排查丢包问题,所以这里主要观察的是错误数、丢包数以及重传数。
根据上面的输出,你可以看到,只有 TCP 协议发生了丢包和重传,分别是:
- 11 次连接失败重试(11 failed connection attempts)
- 4 次重传(4 segments retransmitted)
- 11 次半连接重置(11 resets received for embryonic SYN_RECV sockets)
- 4 次 SYN 重传(TCPSynRetrans)
- 7 次超时(TCPTimeouts)
这个结果告诉我们,TCP 协议有多次超时和失败重试,并且主要错误是半连接重置。换句话说,主要的失败,都是三次握手失败。
不过,虽然在这儿看到了这么多失败,但具体失败的根源还是无法确定。所以,我们还需要继续顺着协议栈来分析。接下来的几层又该如何分析呢?你不妨自己先来思考操作一下,下一节我们继续来一起探讨。

下面是生产环境的完整数据
/tmp]#netstat -s
Ip:
1683658515 total packets received
340 forwarded
0 incoming packets discarded
1683622451 incoming packets delivered
1728458438 requests sent out
9099056 outgoing packets dropped
Icmp:
49431231 ICMP messages received
83049 input ICMP message failed.
ICMP input histogram:
destination unreachable: 49206747
echo requests: 224460
echo replies: 24
49431231 ICMP messages sent
0 ICMP messages failed
ICMP output histogram:
destination unreachable: 49206747
echo request: 24
echo replies: 224460
IcmpMsg:
InType0: 24
InType3: 49206747
InType8: 224460
OutType0: 224460
OutType3: 49206747
OutType8: 24
Tcp:
78687674 active connections openings
15276116 passive connection openings
63172546 failed connection attempts
19791847 connection resets received
340 connections established
1553698421 segments received
1629613317 segments send out
108022 segments retransmited
0 bad segments received.
36033483 resets sent
Udp:
232938 packets received
49073844 packets to unknown port received.
0 packet receive errors
49307001 packets sent
UdpLite:
TcpExt:
114 invalid SYN cookies received
18 packets pruned from receive queue because of socket buffer overrun
12 ICMP packets dropped because they were out-of-window
30510 TCP sockets finished time wait in fast timer
8295195 TCP sockets finished time wait in slow timer
4 passive connections rejected because of time stamp
109534533 delayed acks sent
547 delayed acks further delayed because of locked socket
Quick ack mode was activated 6721 times
167267223 packets directly queued to recvmsg prequeue.
32026299 packets directly received from backlog
2449736681 packets directly received from prequeue
588917805 packets header predicted
7928866 packets header predicted and directly queued to user
142086396 acknowledgments not containing data received
814970084 predicted acknowledgments
3339 times recovered from packet loss due to SACK data
Detected reordering 1 times using FACK
Detected reordering 1 times using time stamp
4 congestion windows fully recovered
1 congestion windows partially recovered using Hoe heuristic
TCPDSACKUndo: 26
154 congestion windows recovered after partial ack
208 TCP data loss events
TCPLostRetransmit: 10
839 timeouts after SACK recovery
3 timeouts in loss state
4500 fast retransmits
1541 forward retransmits
371 retransmits in slow start
50763 other TCP timeouts
135 sack retransmits failed
3 times receiver scheduled too late for direct processing
8866 packets collapsed in receive queue due to low socket buffer
6736 DSACKs sent for old packets
343 DSACKs received
11929374 connections reset due to unexpected data
153421 connections reset due to early user close
70 connections aborted due to timeout
TCPDSACKIgnoredNoUndo: 158
TCPSackShifted: 1
TCPSackMerged: 463
TCPSackShiftFallback: 21108
TCPBacklogDrop: 1
TCPChallengeACK: 3570
TCPSYNChallenge: 1
TCPFromZeroWindowAdv: 287
TCPToZeroWindowAdv: 287
TCPWantZeroWindowAdv: 870914
IpExt:
InMcastPkts: 113809
InBcastPkts: 31073473
InOctets: 654459568091
OutOctets: 503387673001
InMcastOctets: 3641888
InBcastOctets: 3103324037
18 packets pruned from receive queue because of socket buffer overrun
相关推荐
-
传奇世界决战天下(传世决战天下和新决战天下)




曾经刀山驱恶鬼,几度火海战魔神。作为大荒世界的力量象征,《天下3》的世界BOSS向来是少侠们实力集结、共同挑战的目标!如今流光城世界BOSS周公觉醒回归,携全新进阶宝物肆虐大荒,黑恶势力重新崛起,点燃流光大战导火索。少侠们快集结好友,担负起保卫大荒世界的重任吧!【挥师流光决战周公,争夺全新顶级掉落】
-
LOL小炮皮肤事件(英雄联盟小炮全皮肤)




今日英雄联盟测试服对皎月和扎克进行了调整。英雄改动皎月女神 黛安娜基础属性基础法力值由372降低到335。成长法力值由20提升到45。基础攻击速度由0.625提升到0.725。成长攻速由2.25%提升到2.3%。被动-月银之刃AP加成由0.8降低到0.6。移除:不再提供攻击速度加成。移除:不再提供法
-
冒险王之神兵传奇无敌版(冒险王传奇幸运无敌版下载)
由7k7k研发的《冒险王2》新版本“神兵传奇”将于2月6日在91开启新一轮内测。据了解,《冒险王2》早在第一轮内测已掀起了冒险狂潮,吸引了大批忠实玩家的跟随,此次版本升级,更是不负众望,对游戏进行了进一步的优化和改革。尤其在游戏玩法上,在继承了老版本的基本玩法后,新版本更是融入了多样玩法,将带给玩家




版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请通知我们,一经查实,本站将立刻删除。